
本文主要整理了在阅读李航的《统计学习方法》中的学习笔记,阅读过程中参考了很多前人的总结和分析,收获良多。在此无法一一感谢,很多笔记都是拾人牙慧,如有侵权,请告知我将进行修改。
代码实现开源在我的 Github。
支持向量机SVM
一、简介
SVM是一种分类算法,实际上是在数据集中设计出了一个超平面,划分开了所有的样本进而进行分类。划分的依据是样本点距离超平面的间隔最大化,这有别于感知机。svm算法实现了寻找最佳的分类平面,并且借助核技巧,svm可以划分非线性可分样本。
svm的学习策略是间隔最大化,可以形式上为求解一个凸二次规划问题,也等价于正则化的合页损失函数最小化的问题。svm的学习是在特征空间上进行的。
二、什么是间隔
直接开门见山了:可以分为两种间隔,但是都是几何上很容易理解的。
首先是函数间隔 如果我们对w进行规范化,就可以得到升级版的几何间隔:
如果我们对w进行规范化,就可以得到升级版的几何间隔:
三、线性可分支持向量机
利用硬间隔最大化求得最优分离超平面,此时解是唯一的。
超平面:wx+b=0
分类决策函数:f(x = sign(wx+b))
优化问题的转化
最原始问题:
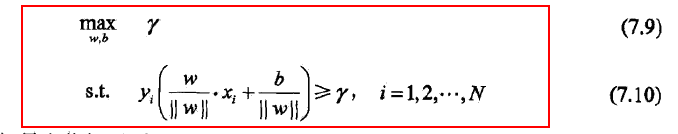
考虑几何间隔,并且变形
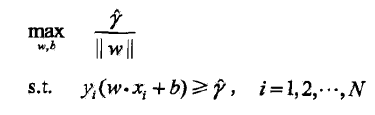
因为gamma是无关项,不影响最优化问题的求解。
为了求解,构造拉格朗日函数,求解对偶问题
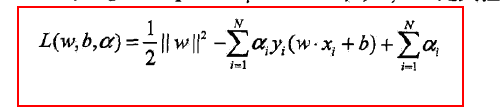
在化为拉格朗日函数之后,原始问题变为极小极大问题,min(w,b)max(a)L(w,b,a),因此对偶问题就是极大极小问题。为了得到对偶问题的解,首先需要求w,b的极小,再求解a的极大。
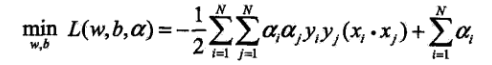
求解a的最大就是对偶问题,
进一步可以转换为求解极小问题。由于满足f(x),c(x)是凸函数,h(x)是仿射的,且满足c(x)<0的条件。
四、线性支持向量机
拓展到线性不可分问题,引入一个松弛变量$\zeta>=0$,约束条件变为$y_i(w*x_i+b)>=1-\zeta_i$

后面具体的推导还是看书和代码叭。
AdaBoost算法
一、概述
提升方法是一种常用的统计学习方法,在分类问题中,通过改变训练样本的权值,学习多个分类器,并且依据一定的权值对这些分类器进行线性组合,提高分类性能。


注意:
- 需要区分开不同的权值,首先是在每次训练新的分类器时,每个样本的权值时不同的,也就是$w_{mi}$表示每个样本的重要程度不同。对于之前预测错误的样本,在新的分类器中会有更大的权重。并且这个权值是需要进行归一化的,如公式8.4
- 对于每一个分类器,在最后的线性组合时也有不同的权重进行线性组合,依据本分类器的对数几率$\alpha_m$.。选择合适的$\alpha_m$也可以让训练误差下降最快。
二、对AdaBoost算法的解释
可以认为该算法是模型为加法模型,损失函数为指数函数,学习算法为前向分步算法的二类分类算法。
为什么选定指数函数作为损失函数?
这是因为极小化指数损失函数等价于最小化分类误差率,并且由于指数损失函数是连续可微的,具有更好的数学性质,因此用它来代替0/1损失函数作为优化目标。
三、提升树
以决策树为基函数的提升方法。针对不同的问题,提升树的学习算法不同,主要区别在于使用损失函数不同。包括使用平方误差函数的回归问题,和使用指数损失函数的分类问题,以及一般损失函数的一般决策问题。
提升树的算法可以应用到回归问题上,

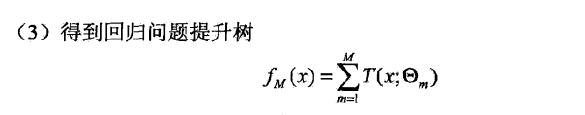
四、梯度提升决策树GBDT


Em算法
一、概述
Em算法是一种迭代算法,用于对含有隐变量的概率模型参数的极大似然估计。或者极大后验概率。
E步,求解期望;M步,求解极大。也成为期望极大算法。
首先解释隐变量,隐变量是指我们无法观测到的变量,这要是我们需要估计的。三个硬币,A硬币的为正面就第二次投掷B硬币,否则投掷C硬币。并且记录第二次投掷的结果作为观测值。因此我们可以想象,最终第二次的结果是可以被观测的,但是第一次投掷的结果其实是隐含在了第一次投掷的结果里。
如果Y表示观测数据,$P(Y| \theta)$其中$\theta$表示需要估计的参量。


从算法可以看出,我们实际上希望得到了一个关于完全数据的分布,并且我们通过最大化完全数据的期望,对隐变量数据进行了估计。
关于Em的推导可以参考这个链接
二、GMM高斯混合统计模型
这里观测量是多个高斯模型混合得到的数据,隐变量是来源于哪个独立高斯分布未知。
我们首先计算出来完全数据的分布函数,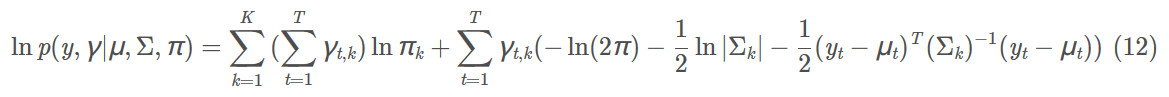
其中,隐变量$\gamma$是我们未知的,我们需要对它进行估计,估计方法就是计算均值(E步),然后对均值最大化,注意,这时均值只与样本有关了,因此我们可以通过最大化这一步,得到参数的估计。进而进行迭代。
下式式计算均值 进而得到对对$\gamma$的估计
进而得到对对$\gamma$的估计
然后进行M步,求导进行寻找实现最大化的参数
三、EM算法的思考
对EM算法的初始化研究
上面介绍的传统EM算法对初始值敏感,聚类结果随不同的初始值而波动较大。总的来说,EM算法收敛的优劣很大程度上取决于其初始参数。
有说法提出,先进行kmeans聚类计算中心,然后将中心作为初值EM算法是否一定收敛?
结论:EM算法可以保证收敛到一个稳定点,即EM算法是一定收敛的。如果EM算法收敛,能否保证收敛到全局最大值?
结论:EM算法可以保证收敛到一个稳定点,但是却不能保证收敛到全局的极大值点,因此它是局部最优的算法,当然,如果我们的优化目标是凸的,则EM算法可以保证收敛到全局最大值,这点和梯度下降法这样的迭代算法相同。
隐马尔可夫模型HMM
是可以用于标注问题的统计学习模型,描述由隐藏的马尔可夫链生成观测序列的过程,属于生成模型。
一、马尔可夫模型
具有三个参数,状态集合(状态转移概率矩阵),观测集合(观测概率矩阵),初始状态概率向量。
这三个参数:
$\lambda:N$个参数
$A:NN$ 对应状态的转移
$B:NM$ 对应每种状态可能的观测值
- 概率计算问题:$P(O|\lambda)$ 给定了一个参数,出现这种观测的概率是多少
- 学习问题:$argmax_{\lambda}P(\lambda|O)$ 给了一个观测值,寻找参数。采用极大似然估计
- 预测问题:$argmax_{I}P(I|O)$ 给了观测变量,推断隐变量,也就是状态。让计算机去标注词性
三、概率计算问题
直接计算的方法复杂度太高$O(TN^T)$
前向算法,给定了前向概率,即t时刻的状态和前面的观测序列。这种方法的复杂度是$O(TN^2)$

同样后向算法,是给定了后向概率,即t时刻的状态和之后观测值。
四、学习算法
监督学习算法:知道观测还知道每个观测对应的状态


非监督算法:BW算法(本质是EM算法)


其中需要带入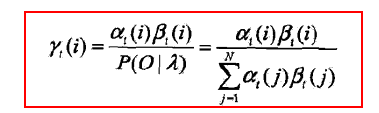
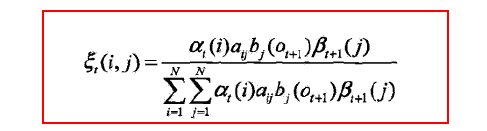
五、预测问题
近似算法
计算出每个时刻的最大的概率的状态,作为实际状态。
存在的问题是,每次都是孤立的考虑,没有考虑前后状态的影响。不是全局最优的。
维特比算法
目标是全局最优$argmaxP(I|O,\lambda)$。采用了动态规划的思想,每次只需要考虑前一个状态就可以。
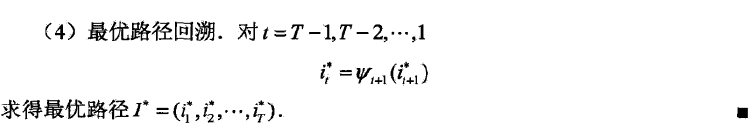
算法中$\delta_t(i)$当前t时刻的状态是qi,且满足观测的最大概率(这个最大概率是说从前面转移来的最大概率/最优路径)。
$\psi_t(i)$表示这个最优路径是从前一个的哪个状态传递得来的。最后进行回溯就可以得到最优的序列。