
本篇,我们来看一下spark内核中另一个重要的模块,Shuffle管理器ShuffleManager。shuffle可以说是分布式计算中最重要的一个概念了,数据的join,聚合去重等操作都需要这个步骤。另一方面,spark之所以比mapReduce的性能高其中一个主要的原因就是对shuffle过程的优化,一方面spark的shuffle过程更好地利用内存(也就是我们前面在分析内存管理时所说的执行内存),另一方面对于shuffle过程中溢写的磁盘文件归并排序和引入索引文件。当然,spark性能高的另一个主要原因还有对计算链的优化,把多步map类型的计算chain在一起,大大减少中间过程的落盘,这也是spark显著区别于mr的地方。
- ShuffleManager
- IndexShuffleBlockResolver
- ExternalSorter
- IndexShuffleBlockResolver.writeIndexFileAndCommit
- 总结
太长不看:
- 一是在数据写入的过程中会由于内存不足从而溢写多个数据文件到磁盘中,而所有的文件都是按照分区和key排序的,这为第二步归并排序打下基础
- 第二步就是将这些溢写的小文件和最后内存中剩下的数据进行归并排序,然后写入一个大文件中,并且在写入的过程中记录每个分区数据在文件中的位移,
- 最后还要写入一个索引文件,索引文件即记录了每个reduce端分区在数据文件中的位移,这样reduce在拉取数据的时候才能很快定位到自己分区所需要的数据
ShuffleManager
spark新版本的Shuffle管理器默认是SortShuffleManager。
前请提要:ShuffleMapTask.runTask
首先我们分析ShuffleManager的调用时机。想一下shuffle的过程,无非就是两个步骤,写和读。
写是在map阶段,将数据按照一定的分区规则归类到不同的分区中。读是在reduce阶段,每个分区从map阶段的输出中拉取属于自己的数据。我们先来分析写的过程,因为对于一个完整的shuffle过程,肯定是先写然后才读的。
回顾一下之前的对作业运行过程的分析,我们应该还记得作业被切分成任务后是在executor端执行的,而Shuffle阶段的的stage被切分成了ShuffleMapTask,shuffle的写过程正是在这个类中完成的,我们看一下代码:
可以看到通过ShuffleManager.getWriter获取了一个shuffle写入器,从而将rdd的计算数据写入磁盘。
1 | override def runTask(context: TaskContext): MapStatus = { |
根据参数得到几种特定的shuffleWriter,包括UnsafeShuffleWriter,BypassMergeSortShuffleWriter,SortShuffleWriter。
ShuffleWriter的类型
抽象类ShuffleWriter定义了将map任务的中间结果输出到磁盘上的功能规范,包括将数据写入磁盘和关闭ShuffleWriter。
SortShuffleWriter提供了对shuffle数据的排序功能。使用ExternalSorted作为排序器,由于ExternalSorted底层使用了PartitionedAppendOnlyMap和PartitionPairBuffer两种缓存,因此支持对shuffle数据的聚合。
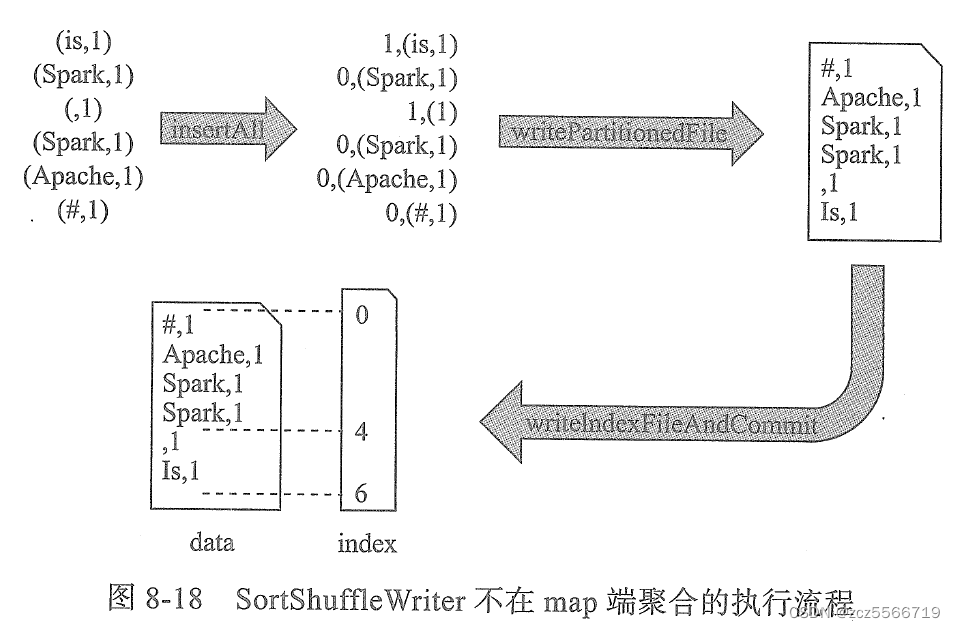
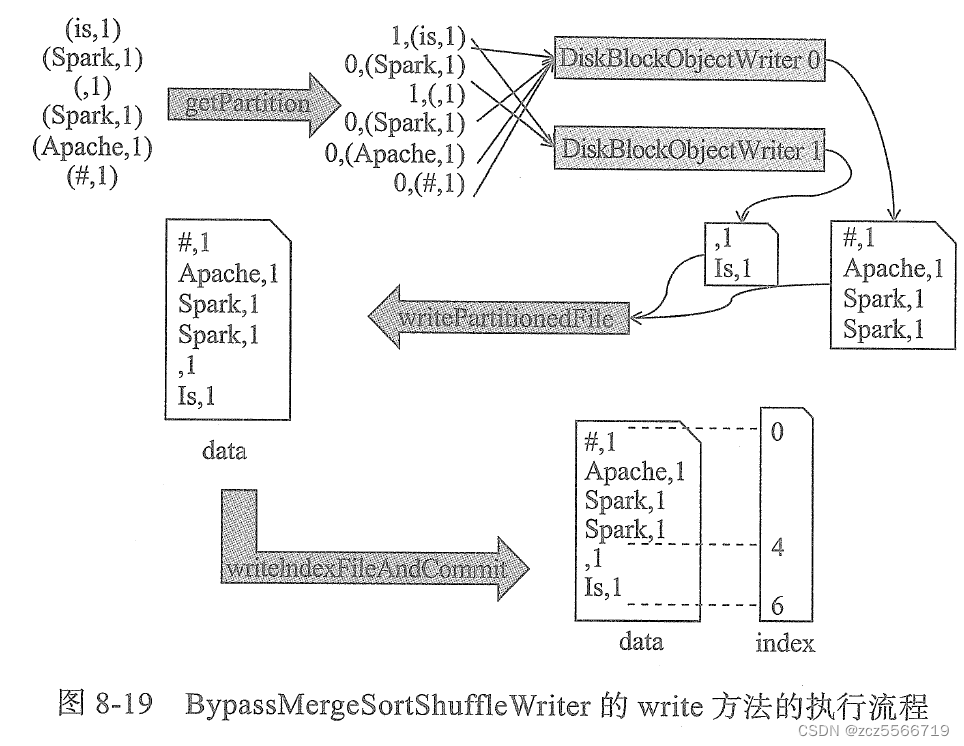
BypassMergeSortShuffleWriter适合在map端不要在持久化数据之前进行聚合、排序的部分操作。这个方法直接把每个分区ID的数据写到一个临时shuffle文件,然后调用BypassMergeSortShuffleWriter的writerPartitionedFile方法,把所有临时shuffle的文件按照分区ID升序写入正式的shuffle数据文件,最后调用IndexShuffleBlockResolver.writeIndexFileAndCommit方法创建一个shuffle索引文件。
UnsafeShuffleWriter使用ShuffleExternalSorter作为外部排序其,所有不具备SortShuffleWriter的聚合功能。并且使用Tungsten的内存作为缓存,提高写入磁盘的性能。
SortShuffleWriter.write
1 | override def write(records: Iterator[Product2[K, V]]): Unit = { |
总结一下这个方法的主要逻辑:
- 首先获取一个排序器,并检查是否有map端的合并器
- 将rdd计算结果数据写入排序器,过程中可能会溢写过个磁盘文件
- 根据shuffleId和分区id获取一个磁盘文件名,
- 最后将多个碎小的溢写文件和内存缓冲区的数据进行归并排序,写到一个文件中
- 将每个分区数据在文件中的偏移量写到一个索引文件中,用于reduce阶段拉取数据时使用
- 返回一个MapStatus对象,封装了当前executor上的blockManager的id和每个分区在数据文件中的位移量
- 在stop方法中还会做一些收尾工作,统计磁盘io耗时,删除中间溢写文件
IndexShuffleBlockResolver
特质ShuffleBlockResolver定义了对shuffle Block进行解析的规范,包括获取shuffle数据文件,获取shuffle索引文件,删除指定的shuffle数据文件和索引文件,生成shuffle索引文件,获取shuffle块的数据。
IndexShuffleBlockResolver是唯一的实现类,用户维护和创建shuffle block与物理文件位置之间的映射关系。
我们首先看一下获取shuffle输出文件名,是通过IndexShuffleBlockResolver组件获取的,而它的内部又是通过BlockManager内部的DiskBlockManager分配文件名的,这个DiskBlockManage我在之前分析块管理器时提到过,它的作用就是管理文件名的分配,以及spark使用的目录,子目录的创建删除等。我们看到对于数据文件和索引文件的命名规则是不一样的,他们的命名规则分别定义在ShuffleDataBlockId和ShuffleIndexBlockId中。
1 | // 获取shuffle数据文件 |
ExternalSorter
ExternalSorter.insertAll
我们根据SortShuffleWriter中的调用顺序,首先看一下ExternalSorter.insertAll方法:
首选根据是否在在map端合并分为两种情况,这两种情况使用的内存存储结构也不一样,对于在map端合并的情况使用的是PartitionedAppendOnlyMap结构,不在map合并则使用PartitionedPairBuffer。其中,PartitionedAppendOnlyMap是用数组和线性探测法实现的map结构。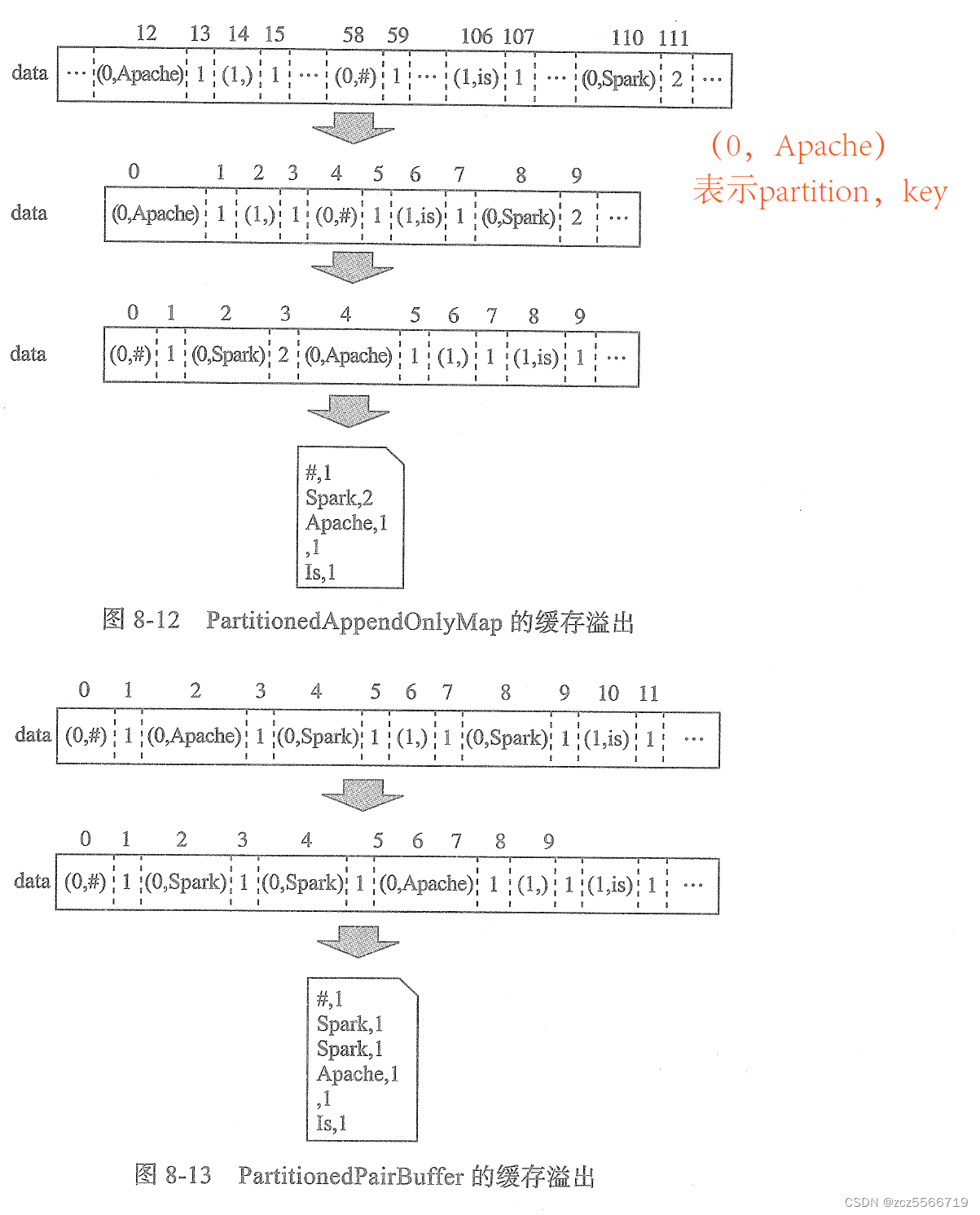
PartitionedAppendOnlyMap的底层存储是散列存储:
- 需要先将data数组中的元素向低索引整理;
- 然后将data数组中的元素根据执行的比较器对元素进行排序。如果指定了的聚合函数或者排序函数,那么排序先按照分区ID进行排序,然后按照key进行排序。
- 将data数组中的数据通过迭代器写到磁盘文件。
PartitionPairBuffer与之类似,只是底层data数组中的元素是在插入的时候就排列整齐的,不需要整理的操作。
然后将数据一条一条地循环插入内存的存储结构中,同时考虑到map端合并的情况
1 | def insertAll(records: Iterator[Product2[K, V]]): Unit = { |
AppendOnlyMap.changeValue
我们看一个稍微复杂一点的结构,AppendOnlyMap。类似Java Hashmap,但是可以额外处理null指。
首先考虑空值的情况:计算key的hash,然后对容量取余。注意,这里由于容量是2的整数次幂,所以对容量取余的操作等同于和容量-1进行位与操作,java HashMap中的操作。
如果,不存在旧值,那么直接插入。
如果存在旧值,更新旧值。
如果发生hash碰撞,那么需要向后探测,并且是跳跃性的探测。
可以看出,这个结构设计还是很精良的,这里面有个很重的方法,incrementSize方法中会判断当前数据量的大小,如果超过阈值就会扩容,这个扩容的方法比较复杂,就是一个重新hash再分布的过程,不过有一点,发不论是在插入新数据还是重新hash再分布的过程中,对于hash碰撞的处理策略一定要相同,否则可能造成不一致。
changeValue方法实现了缓存聚合算法。
1 | // 向数组中插入一个kv对, |

ExternalSorter.maybeSpillCollection
我们回到ExternalSorter的插入方法中,每插入一条数据都要检查内存占用,判断是否需要溢写到磁盘,如果需要就溢写到磁盘。
这个方法里调用了map.estimateSize来估算当前插入的数据的内存占用大小,对于内存占用的追踪和估算的功能是在SizeTracker特质中实现的,这个特质我在之前分析MemoryStore时提到过,在将对象类型的数据插入内存中时使用了一个中间态的数据结构DeserializedValuesHolder,它的内部有一个SizeTrackingVector,这个类就是通过继承SizeTracker特征从而实现对象大小的追踪和估算。
1 | private def maybeSpillCollection(usingMap: Boolean): Unit = { |
ExternalSorter.maybeSpill
首先检查当前内存占用是否超过阈值,如果超过会申请一次执行内存,如果没有申请到足够的执行内存,那么依然需要溢写到磁盘。
1 | protected def maybeSpill(collection: C, currentMemory: Long): Boolean = { |
ExternalSorter.spill
接着上面的方法,
1 | override protected[this] def spill(collection: WritablePartitionedPairCollection[K, C]): Unit = { |
WritablePartitionedPairCollection.destructiveSortedWritablePartitionedIterator
这个方法返回按照分区和key排序过的迭代器,其具体的排序逻辑在AppendOnlyMap.destructiveSortedIterator中
AppendOnlyMap.destructiveSortedIterator
这段代码分为两块,首先对数组进行压紧,是的稀疏的数据全部转移到数组的头部;
然后对数组按照比较器进行排序,比较器首先是按照分区进行比较,如果分区相同才按照key进行比较;
然后返回一个迭代器,这个迭代器仅仅是对数组的封装。通过这个方法,我们大概知道了AppendonlyMap的排序逻辑。
1 | def destructiveSortedIterator(keyComparator: Comparator[K]): Iterator[(K, V)] = { |
ExternalSorter.spillMemoryIteratorToDisk
回到ExternalSorter.spill方法中,在获取了经过排序后 的迭代器之后,我们就可以将数据溢写到磁盘上了。
这个方法的代码我不贴了,总结一下主要步骤:
- 首先通过DiskBlockManager获取一个临时块的BlockId和临时文件名
- 通过blockManager获取一个磁盘写入器,即DiskBlockObjectWriter对象,内部封装了调用java流api写文件的逻辑
- 循环将每条数据写入磁盘,并定期进行刷写(每隔一定的数据条数将内存中的数据刷写到磁盘上)
- 如果发生异常,则会对之前写入的文件进行回滚
小结
总结一下数据通过ExternalSorter向磁盘溢写的全过程:
- 首先,数据会被一条一条地向内部的map结构中插入
- 每插入一条数据都会检查内存占用情况,如果内存占用超过阈值,并且申请不到足够的执行内存,就会将目前内存中的数据溢写到磁盘
- 对于溢写的过程:首先会将数据按照分区和key进行排序,相同分区的数据排在一起,然后根据提供的排序器按照key的顺序排;然后通过DiskBlockManager和BlockManager获取DiskBlockWriter将数据写入磁盘形成一个文件。
- 将溢写的文件信息,在整个写入过程中,会溢写多个文件
ExternalSorter.writePartitionedFile
总结一下主要的步骤:
仍然是通过blockManager获取一个磁盘写入器.
将内部溢写的多个磁盘文件和滞留在内存的数据进行归并排序,并分装成一个按照分区归类的迭代器
循环将数据写入磁盘,每当一个分区的数据写完后,进行一次刷写,将数据从os的文件缓冲区同步到磁盘上,然后获取此时的文件长度,记录下每个分区在文件中的位移
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53def writePartitionedFile(
blockId: BlockId,
outputFile: File): Array[Long] = {
// Track location of each range in the output file
val lengths = new Array[Long](numPartitions)
val writer = blockManager.getDiskWriter(blockId, outputFile, serInstance, fileBufferSize,
context.taskMetrics().shuffleWriteMetrics)
// 如果前面没有数据溢写到磁盘中,
// 则只需要将内存中的数据溢写到磁盘
if (spills.isEmpty) {
// Case where we only have in-memory data
val collection = if (aggregator.isDefined) map else buffer
// 返回排序后的迭代器
val it = collection.destructiveSortedWritablePartitionedIterator(comparator)
while (it.hasNext) {
val partitionId = it.nextPartition()
while (it.hasNext && it.nextPartition() == partitionId) {
it.writeNext(writer)
}
// 写完一个分区刷写一次
val segment = writer.commitAndGet()
// 记录下分区的数据在文件中的位移
lengths(partitionId) = segment.length
}
} else {// 有溢写到磁盘的文件
// We must perform merge-sort; get an iterator by partition and write everything directly.
// 封装一个用于归并各个溢写文件以及内存缓冲区数据的迭代器
// TODO 这个封装的迭代器是实现归并排序的关键
for ((id, elements) <- this.partitionedIterator) {
if (elements.hasNext) {
for (elem <- elements) {
writer.write(elem._1, elem._2)
}
// 每写完一个分区,主动刷写一次,获取文件位移,
// 这个位移就是写入的分区的位移,
// reduce端在拉取数据时就会根据这个位移直接找到应该拉取的数据的位置
val segment = writer.commitAndGet()
lengths(id) = segment.length
}
}
}
writer.close()
// 写完后更新一些统计信息
context.taskMetrics().incMemoryBytesSpilled(memoryBytesSpilled)
context.taskMetrics().incDiskBytesSpilled(diskBytesSpilled)
context.taskMetrics().incPeakExecutionMemory(peakMemoryUsedBytes)
// 返回每个reduce端分区数据在文件中的位移信息
lengths
}IndexShuffleBlockResolver.writeIndexFileAndCommit
仍然回到SortShuffleWriter.write方法,最后一步调用了IndexShuffleBlockResolver.writeIndexFileAndCommit方法,这个方法的作用主要是将每个的分区的位移值写入到一个索引文件中,并将临时的索引文件和临时的数据文件重命名为正常的文件名(重命名操作是一个原子操作)
总结
总结shuffle写数据的过程,可以分为两个主要的步骤:
- 一是在数据写入的过程中会由于内存不足从而溢写多个数据文件到磁盘中,而所有的文件都是按照分区和key排序的,这为第二步归并排序打下基础
- 第二步就是将这些溢写的小文件和最后内存中剩下的数据进行归并排序,然后写入一个大文件中,并且在写入的过程中记录每个分区数据在文件中的位移,
- 最后还要写入一个索引文件,索引文件即记录了每个reduce端分区在数据文件中的位移,这样reduce在拉取数据的时候才能很快定位到自己分区所需要的数据